VANI (वाणी)
One of the top 5 teams to win Lightweight, Multi-speaker, Multi-lingual Indic Text-to-Speech grand challenge organized as part of IEEE ICASSP 2023.
VANI: Very-lightweight Accent-controllable TTS for Native and Non-native speakers with Identity Preservation
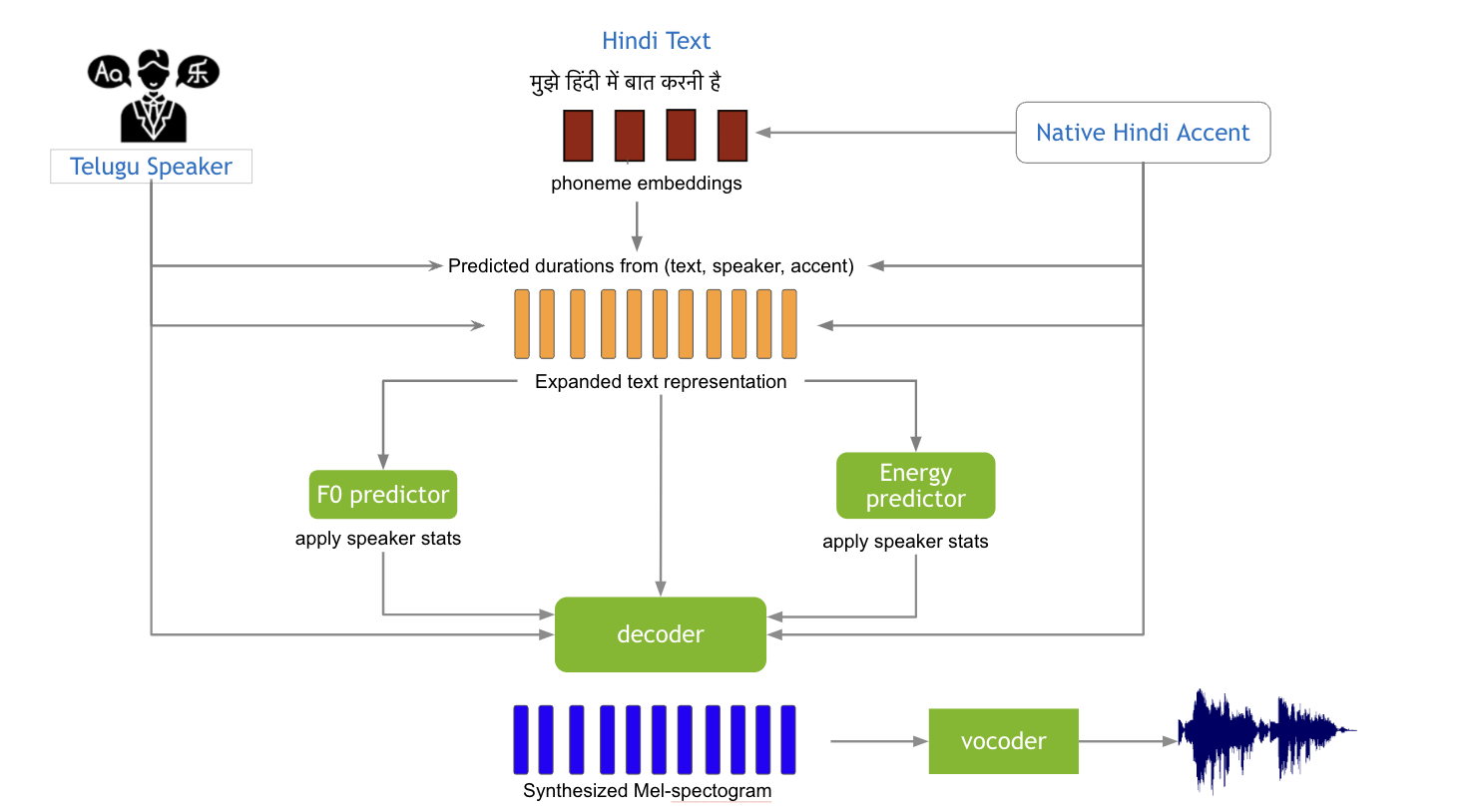
We introduce VANI (वाणी), a very lightweight multi-lingual accent controllable speech synthesis system. Our model builds upon disentanglement strategies proposed in RADMMM1,2 and supports explicit control of accent, language, speaker and fine-grained F0 and energy features for speech synthesis. We utilize the Indic languages dataset, released for LIMMITS 20233 as part of ICASSP Signal Processing Grand Challenge, to synthesize speech in 3 different languages. Our model supports transferring the language of a speaker while retaining their voice and the native accent of the target language. We utilize the large-parameter RADMMM model for Track 1 and lightweight VANI model for Track 2 and 3 of the competition.
Checkout our NVIDIA GTC 2024 talk in San Jose, California, USA: Speaking in Every Language: A Quick-Start Guide to TTS Models for Accented, Multilingual Communication [S62517]
Checkout my substack blog about this project here.
Audio Samples
Here are the input text (and their respective translations):
- हिंदी (Hindi): “स्थानीय लोगों ने जख्मियों को सिविल अस्पताल आनंदपुर साहिब में भर्ती करवाया”
- In English: “Local people admitted the injured to Civil Hospital Anandpur Sahib.”
- मराठी (Marathi): “गुलाबी ओठांसाठी ताज्या लाल गुलाबाच्या पाकळ्या वाटून मध आणि लोण्यात मिसळून लावावे.”
- In English: “For pink lips, apply fresh red rose petals mixed with honey and butter.”
- తెలుగు (Telugu): “ఈ చికిత్స విధానంలో మూల కణాలను తీసేటప్పుడు దాతలు ఒక్కింత నొప్పితో పాటు కొంత బాధ భరించాల్సి వస్తొంది”
- In English: “In this treatment procedure, the donors have to endure some pain as well as some discomfort while the stem cells are being extracted”
Track 1 (Large-parameter setup, Small-data using RAD-MMM):
| Speakers / Languages | |||
|---|---|---|---|
| Native Hindi - Female | |||
| Native Hindi - Male | |||
| Native Marathi Female | |||
| Native Marathi - Male | |||
| Native Telugu - Female | |||
| Native Telugu - Male |
Track 2 (Small-parameter, Large-data setup using VANI):
| Speakers / Languages | |||
|---|---|---|---|
| Native Hindi - Female | |||
| Native Hindi - Male | |||
| Native Marathi Female | |||
| Native Marathi - Male | |||
| Native Telugu - Female | |||
| Native Telugu - Male |
Track 3 (Small-parameter, Small-data setup using VANI):
| Speakers / Languages | |||
|---|---|---|---|
| Native Hindi - Female | |||
| Native Hindi - Male | |||
| Native Marathi Female | |||
| Native Marathi - Male | |||
| Native Telugu - Female | |||
| Native Telugu - Male |
Collaborators
- Rohan Badlani, Machine Learning Researcher, NVIDIA
- Subhankar Ghosh, Senior Applied Scientist, NVIDIA
- Rafael Valle, Research Manager and Scientist, NVIDIA
- Kevin J. Shih, Senior Research Scientist, NVIDIA
- João Felipe Santos, Senior Research Scientist, NVIDIA
- Boris Ginsburg, Senior Director, Conversational AI, NVIDIA
- Bryan Catanzaro, Vice President, Applied Deep Learning Research, NVIDIA
Acknowledgements
The authors would like to thank Roman Korostik for discussions on spectogram enhancement, Evelina Bakhturina for discussions on dataset cleanup and Sirisha Rella for Telugu evaluation.
References
-
Rohan Badlani, Rafael Valle, Kevin J. Shih, João Felipe Santos, Siddharth Gururani, and Bryan Catanzaro, “Radmmm: Multilingual multiaccented multispeaker text to speech,” arXiv, 2023. ↩