Deep Knowledge Tracing
Independent Study under the guidance of Prof. Michael C. Mozer (Spring 2018).
View the Project on GitHub aroraakshit/deep_knowledge_tracing
Research Overview
Personalized learning environments requiring the elicitation of the knowledge state of the learner have inspired researchers to propose distinct models to understand that knowledge state. Recently, the spotlight has shone on comparisons between traditional, interpretable models such as Bayesian Knowledge Tracing (BKT) and its variants, and complex, opaque neural network models such as Deep Knowledge Tracing (DKT). Although the performance of these models can be similar, BKT can be at a distinct disadvantage relative to DKT for example when it comes to exploiting inter-skill similarities.
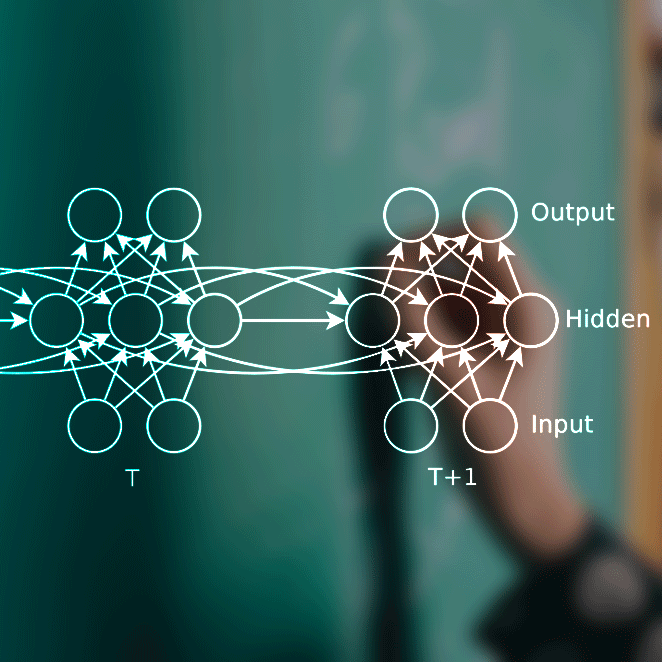
In this study, we explore the superiority of DKT by building a version of DKT that is trained in exactly the same manner as BKT: sequences of a single skill are input, and a different DKT model is trained for each skill. We built a recurrent neural networks (RNNs), in particular a Long Short Term Memory (LSTM), to model a learner’s knowledge state using a dataset of grade-school students mastering ten core math skills via an adaptive learning environment (WootMath).
We trained the network in two ways, either presenting a single sequence for each learner that involved trials of many different skills, or a separate sequence for each learner and each skill. Combining predictions across skills for each model, we estimate the prediction quality via the AUC. The results indicate that the inductive bias of BKT could be helpful for the model’s performance. The BKT model has relatively few parameters to be tuned and in this way well constrained by the data.
UPDATE: Won ‘Outstanding MS Poster Award’ at Graduate Research Expo (organized by Computer Science Department, CU Boulder). Poster Link
{kind=link}
Collaborators
- Dr. Shirly Montero, Ph.D. student at University of Colorado Boulder
- Dr. Sean Kelly, VP Engineering and Co-Founder at Woot Math
- Dr. Brent Milne, VP Research and Co-Founder at Woot Math
Technologies Used
- TensorFlow, Docker, Pandas, Scikit-learn, Jupyter, Seaborn, Matplotlib
Acknowledgements
The authors wish to thank Dr. Mohammad Khajah for many useful discussions.